How AI is helping to amplify science communication
Learn how Gubbi Labs is harnessing Generative AI and LLM’s to simplify complex research, produce science stories, and generate regional-language podcasts—bringing scientific knowledge closer to the public than ever before

Gubbi Labs editorial team during an interaction with members joining remotely.
By: Sudhira HS and Dennis C Joy
It was around 2022 when Generative AI powered by large language models (LLM) were taking shape. We were keenly following the releases of GPT-1 (in 2018) and GPT-2 (in 2019) by OpenAI, with emerging applications and promises it held. Based on this, we wrote an article in February 2022, in our native language of Kannada, on how this technology could potentially transform the science communication landscape. The article concluded with a hypothetical note stating that by 2025, one could simply provide an outline, and such models could write the entire news story.
By 2025, this has indeed turned out to be true!
At Gubbi Labs, we began in 2014 with a grand mission to raise the bar on scientific literacy in India. We started by writing popular stories based on published research papers. For a long time, our team of writers and editors has meticulously reviewed research papers and then translated them into concise and engaging stories. With over 2,500 popular stories published to date (available on https://researchmatters.in), we have seen how difficult it is to work on papers from different domains/topics with varying complexities and jargon.

The emergence of LLMs offered the promise to fast-track the process. This idea finally took shape in December 2024, thanks to the JournalismAI Innovation Challenge, supported by the Google News Initiative. Out of over 700 applicants, Gubbi Labs was one of the 35 global newsrooms (and among the only two from India) selected for the JournalismAI Innovation Challenge, which provided the much-needed resources and energy for a project we had initially struggled with.
We are now on a grander mission to revolutionise science communication using the power of AI, specifically Generative AI and LLMs. Our vision is to create a product that can automatically identify recent research papers, assess their newsworthiness, and then generate ready-to-use storylines, summaries, and social media content for our editors. We aim to produce science news articles and updates that are not only accurate but also engaging and accessible to high school students and lay readers of a newspaper.
As part of the challenge, the JournalismAI team helped us articulate and structure this endeavour into a series of focused "sprints", each tackling a specific aspect of our goal. One of our foremost actions was to formulate a Generative AI policy that addresses the use of AI and AI-assisted technologies in content creation. The policy aims to promote transparency, integrity, and quality in our publications. It also provides guidelines for our writers and contributors on the responsible and ethical use of these technologies when creating content for our portal.
Diving deep into LLM research
In the first sprint, our first primary task involved exploring the vast landscape of LLMs to determine which models were best suited for summarising complex research papers. We rigorously evaluated a range of models, including OpenAI's series (GPT-4, GPT-4o), Gemini, Llama, Grok, and various open-source options from Hugging Face. After our editors reviewed the initial summaries, we narrowed down our choices to four specific LLMs: Llama 3.2 3B Instruct (open-source), DeepSeek-R1-Distill-Qwen-7B (open-source), Gemini 2.0 Flash (proprietary), and OpenAI GPT-4o (proprietary). We used five diverse research papers from Indian institutions for our initial summarisation tests.
We quickly encountered our first significant roadblock: automatically extracting content from PDF journal articles. This proved challenging because scientific papers often lack consistent formatting across different journals and even within the same journal. Variations in subsection titles, author names, institution details, image annotations, and even column layouts made automated extraction difficult. Early LLMs struggled, often reading multi-column documents as continuous text. This limitation, coupled with the lack of capable Retrieval-Augmented Generation (RAG) at the time, led to summaries with incorrect information, especially regarding authors, institutions, and even the core premise of the paper, sometimes resulting in "non-sensical and often whimsical summaries". Our temporary solution was to manually copy the text into a Google Docx file before feeding it to the LLM. Happily, later LLM releases with file upload options have since resolved this issue.
In terms of performance, OpenAI GPT-4o and Gemini 2.0 Flash performed surprisingly well. However, the outputs from the open-source Llama 3.2 3B Instruct and DeepSeek-R1-Distill-Qwen-7B were often riddled with hallucinations and strange contexts. For instance, Llama imagined scenarios completely detached from reality. DeepSeek, meanwhile, produced grammatically incorrect and obvious statements like "Imagine a world where smoking is not just an (sic) habit but a serious health threat", imagining a world we already know.
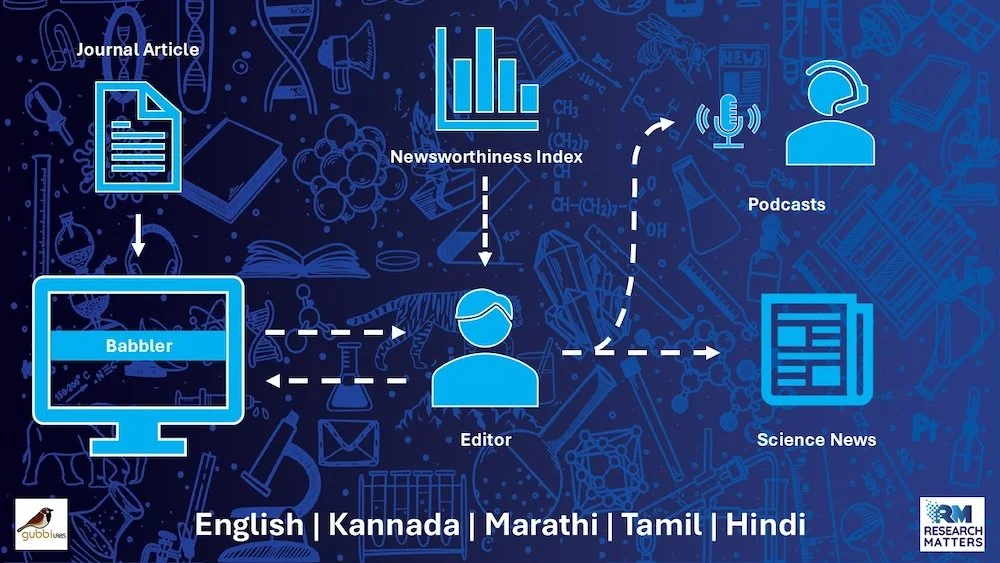
Science communication pipeline leveraging GenAI through Research Matters' Babbler.
Crafting the perfect prompts and evaluating performance
With promising LLMs identified, our next step was to figure out how to correctly prompt them to generate content effectively. This sprint focused on Prompt Development and Evaluation. After considerable research and many iterations, we developed three distinct prompt types: basic, intermediate and advanced.
To quantitatively assess the LLMs, we used ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrics, which compare how well automatically generated summaries capture information compared to human-written ones. We generated 60 summaries in total (4 LLMs x 5 papers x 3 prompt types) and compared them against existing human-written stories to calculate ROUGE scores.
The results confirmed that advanced prompts generally yielded slightly better results. Between the models, OpenAI GPT-4o-mini and Google Gemini 2.0 showed comparable performance, consistently outperforming the others. Both manual editor assessments and ROUGE scores pointed to Gemini 2.0 performing better overall, closely followed by OpenAI GPT-4o, leading to their selection for product development.
Generating social media collateral and multimedia
Beyond just generating articles, we aimed to amplify their reach across various social media platforms. This sprint focused on creating tailored social media content for the generated news stories, targeting platforms such as the Research Matters website, popular news aggregator, Twitter/X, Facebook, and LinkedIn. We developed concise, platform-specific prompts to generate content, such as simple, engaging headlines for character-limited platforms like Twitter/X, captivating headlines and detailed summaries for Facebook, and professional titles and summaries for LinkedIn.
We also ventured into producing multimedia outputs, a significant step towards diversifying our reach. A key task was converting stories into audio podcasts and summaries specifically for an Indian audience, either in regional languages or English with an Indian accent. After numerous trials, we successfully developed a workflow using a combination of AI-backed tools to create audio podcasts in Kannada (an Indian language) based on our generated stories. We are also actively working on generating English podcasts and audio summaries with an Indian accent.
Building the application prototype
In recent weeks, our focus has shifted to integrating all these components by developing the backend necessary to automate the GenAI usage for article generation. We now have a prototype web application built using Python. This programme sets up a virtual environment, runs a preferred GenAI model using its API Key, and then feeds the selected research paper (as a PDF) and the relevant prompts to the model. Currently, the programme produces two text files: one for the article based on the research paper and another for the social media collateral.
Research on newsworthiness index
Moving on, one of the aspects we are most excited about in this project is the work centred around the development of a newsworthiness index. The primary goal of this sprint is to design and implement a scoring system to rank research papers based on their newsworthiness, thereby ensuring optimal article selection for our product. This addresses a significant challenge faced by most science news editors, who encounter an overwhelming volume of new peer-reviewed publications daily. Manually sifting through these to identify truly "newsworthy" papers is not only time-consuming but also subjective. Our aim is to provide a systematic, data-driven approach to highlight papers with the highest potential for popular news stories.
The newsworthiness index is built upon several key characteristics: prominence, authoritativeness, topicality/relevance, and freshness, which align with how Google News selects and prioritises news stories published by various newsrooms. These components are combined using a weighted sum model, after normalising each score to a 0-1 scale, with appropriate weights assigned to the factors. The project has already developed a Python-based configurable tool that processes a database of research papers to generate a newsworthiness-ranked list of papers. One of the ongoing challenges, however, is the difficulty in directly quantifying "relevance" or "interest" for specific scientific papers based on general public trends, as most specialised Science, Technology, Engineering, and Mathematics (STEM) subjects don't consistently trend on public platforms, and Google Trends provides limited insights for very broad themes.
Moving forward
Overall, the output from our selected LLMs has been excellent, capturing many details from research publications, including introductions, methodologies, results, and even correctly identifying individuals and institutions.
Encouragingly, the rapid development of AI tools has been a game-changer. The release of more advanced "reasoning" models like Gemini version 2.5 and OpenAI’s Omni series has drastically improved summarisation for complex research topics. This experience has highlighted a crucial insight: many issues encountered with AI capabilities are temporary, allowing us to focus on our broader goal of expanding science communication.
Looking ahead, we plan to continue refining our prompts and evaluation methods using a larger sample of our existing science news stories. Soon, we will also focus on developing the application's front-end and hosting using our newsworthiness index. The recent launch of audio conversion generation in five Indian regional languages by Notebook LM is an exciting prospect, and we are now looking to convert our generated articles into smaller audio bytes and podcasts in various Indian languages.
This project has been an incredible journey of exploration and development, and we are incredibly excited about the potential of AI to truly amplify science communication and diversify its reach, making complex science accessible to everyone.
———
This article is part of a series providing updates from 35 grantees on the JournalismAI Innovation Challenge, supported by the Google News Initiative. Click here to read other articles from our grantees.